
La Biblioteca Epstein del sitio web del DOJ es un ejemplo de desorganización. A principios de diciembre, Keller revisaba las decenas de miles de páginas de documentos en la biblioteca y sentía frustración ante el caos: archivos de cientos de páginas, texto a veces borroso o torcido, una transferencia bancaria sin contexto, una cadena de correos electrónicos con la mitad de los nombres tachados, un registro de vuelo con solo iniciales. «Es desconcertante. Estás leyendo fragmentos de algo enorme e intentando descifrar qué fragmentos importan y cómo se relacionan».
Una noche, pasó unas cuatro horas intentando rastrear el nombre de una sola persona en unos 30 documentos del archivo. «Me detuve y pensé: estoy haciendo a mano lo que una base de datos podría hacer en milisegundos». Como desarrollador de infraestructura de bases de datos en una empresa, sabía exactamente qué hacer a continuación. «Abrí un editor de código y empecé a crear. A las 3 de la mañana ya tenía un prototipo de búsqueda básica que funcionaba con unos cientos de documentos».
Por aquel entonces, un sitio llamado Jmail.world estaba causando sensación como herramienta para que la gente examinara los correos electrónicos de Epstein como si utilizara una interfaz de Gmail. Lanzado a mediados de noviembre y creado por un grupo de voluntarios expertos en tecnología, ha crecido desde entonces para incluir, entre otras cosas, sus fotos, vuelos e historial de compras en Amazon, también mostrados como si el lector estuviera viendo las propias cuentas de Epstein. Keller utilizó la herramienta y le gustó: «Jmail era la prueba de que la comunidad podía crear herramientas mejores que las que ofrecía el gobierno».
También le ayudó a perfeccionar su propio proyecto. «En lugar de pensar en una categoría de documentos, empecé a pensar en la red. ¿Cómo relacionar a una persona que aparece en un correo electrónico con un vuelo en el que estuvo, con una transferencia bancaria, con una declaración que prestó? Ese problema de referencias cruzadas es lo que quería resolver».
Entonces, el 19 de diciembre, el DOJ publicó su primer gran tramo, añadiendo cientos de miles de nuevos documentos al archivo existente. Inmediatamente, la carga de trabajo de Keller se disparó. El prototipo que había construido a principios de mes se convirtió en la base para procesarlo todo.
La mayoría de las noches trabajaba hasta las 3 o las 4 de la madrugada, sorbiendo café frío mientras navegaba por un mar de pestañas abiertas.
Debido a su infancia, dice, «cuando empezaron a caer los primeros documentos, no podía apartar la vista. Entendía a nivel visceral lo que se describía en esos archivos». Por las tardes, volvía a casa de su trabajo y, una vez que todos los miembros de su familia estaban dormidos, se refugiaba en su despacho y pasaba horas hojeando los PDF descargados.
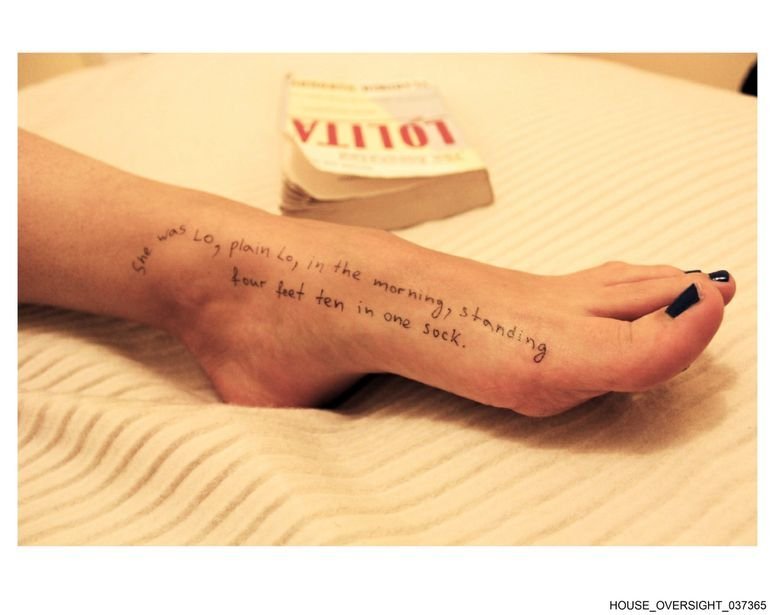
La última filtración de fotos de los demócratas del Comité de Supervisión de la Cámara de Representantes de EE UU incluye a más hombres famosos y citas de la novela Lolita escritas en el cuerpo de una mujer.
Cómo se construyó Epsteinexposed.com
Muchos documentos se publicaban como imágenes, y él pasaba cada página por varios programas para convertirlos en texto que pudiera buscarse; a veces, un sistema no conseguía convertir el texto y él lo pasaba por un segundo o un tercero. Luego utilizaba otro sistema para extraer datos importantes como nombres, organizaciones, fechas y lugares. Llevaba a cabo una verificación de hash, proceso que comprueba si los archivos del DOJ han sido manipulados, y un análisis de redacción, para buscar incoherencias en la forma en que el gobierno tacha la información. Hacía un seguimiento de todo su trabajo en un meticuloso libro de contabilidad digital codificado por colores. «No se trata de subir archivos. Es reconstruir la escena de un crimen a partir de 2 millones de fragmentos de pruebas».
A finales de enero, el DOJ publicó un lote aún mayor, con más de 3 millones de archivos. Aunque la carga de trabajo aumentó aún más de la noche a la mañana, Keller afirma que la publicación de archivos fue una confirmación de su eficacia. Al fin y al cabo, todo el sistema que había estado desarrollando había sido diseñado para ese momento.












